Explore the revolutionary platform, QLoRa, which empowers AI enthusiasts to fine-tune massive language models on their personal GPUs. This blog will guide you through the transformative journey of leveraging the power of AI, made convenient and accessible through QLora.
Source from Benjamin Marie’s post
Most large language models (LLM) are too big to be fine-tuned on consumer hardware. For instance, to fine-tune a 65 billion parameters model we need more than 780 Gb of GPU memory. This is equivalent to ten A100 80 Gb GPUs. In other words, you would need cloud computing to fine-tune your models.
Now, with QLoRa (Dettmers et al., 2023), you could do it with only one A100.
In this blog post, I will introduce QLoRa. I will briefly describe how it works and we will see how to use it to fine-tune a GPT model with 20 billion parameters, on your GPU.
Note: I used my own nVidia RTX 3060 12 Gb to run all the commands in this post. You can also use a free instance of Google Colab to achieve the same results. If you want to use a GPU with a smaller memory, you would have to use a smaller LLM.
QLoRa: Quantized LLMs with Low-Rank Adapters
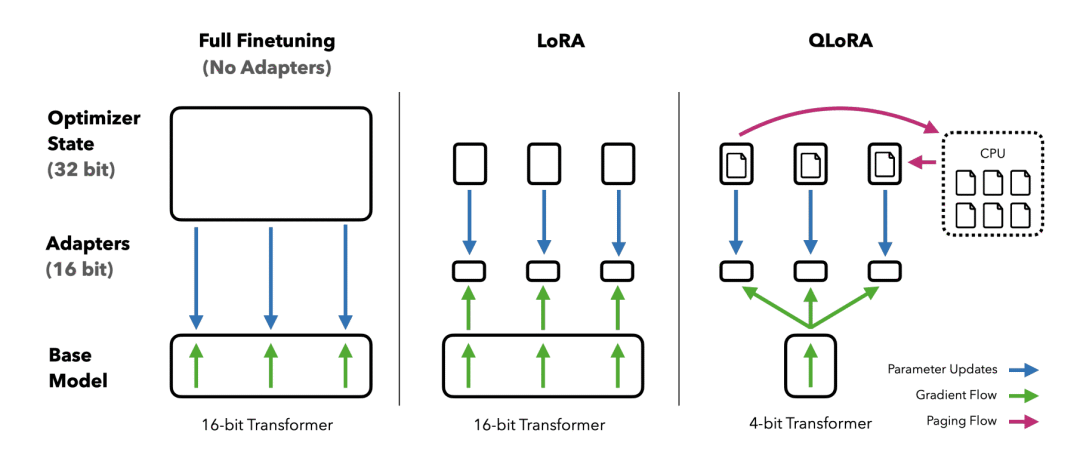
In June 2021, Hu et al. (2021) introduced low-rank adapters (LoRa) for LLMs.
LoRa adds a tiny amount of trainable parameters, i.e., adapters, for each layer of the LLM and freezes all the original parameters. For fine-tuning, we only have to update the adapter weights which significantly reduces the memory footprint.
QLoRa goes three steps further by introducing: 4-bit quantization, double quantization, and the exploitation of nVidia unified memory for paging.
In a few words, each one of these steps works as follows:
- 4-bit NormalFloat quantization: This is a method that improves upon quantile quantization. It ensures an equal number of values in each quantization bin. This avoids computational issues and errors for outlier values.
- Double quantization: The authors of QLoRa defines it as follows: “the process of quantizing the quantization constants for additional memory savings.”
- Paging with unified memory: It relies on the NVIDIA Unified Memory feature and automatically handles page-to-page transfers between the CPU and GPU. It ensures error-free GPU processing, especially in situations where the GPU may run out of memory.
All of these steps drastically reduce the memory requirements for fine-tuning, while performing almost on par with standard fine-tuning.
Fine-tuning a GPT model with QLoRa
Hardware requirements for QLoRa:
- GPU: The following demo works on a GPU with 12 Gb of VRAM, for a model with less than 20 billion parameters, e.g., GPT-J. For instance, I ran it with my RTX 3060 12 Gb. If you have a bigger card with 24 Gb of VRAM, you can do it with a 20 billion parameter model, e.g., GPT-NeoX-20b.
- RAM: I recommend a minimum of 6 Gb. Most recent computers have enough RAM.
- Hard drive: GPT-J and GPT-NeoX-20b are both very big models. I recommend at least 80 Gb of free space.
If your machine doesn’t meet these requirements, the free instance of Google Colab would be enough instead.
Software requirements for QLoRa:
We need CUDA. Make sure it is installed on your machine.
We will also need to install all the dependencies:
- bitsandbytes: A library that contains all we need to quantize an LLM.
- Hugging Face Transformers and Accelerate: These are standard libraries that are used to efficiently train models from Hugging Face Hub.
- PEFT: A library that provides the implementations for various methods to only fine-tune a small number of (extra) model parameters. We need it for LoRa.
- Datasets: This one is not a requirement. We will only use it to get a dataset for fine-tuning. Of course, you can provide instead your own dataset.
We can get all of them with PIP:
pip install -q -U bitsandbytes
pip install -q -U git+https://github.com/huggingface/transformers.git
pip install -q -U git+https://github.com/huggingface/peft.git
#pip install -q -U git+https://github.com/huggingface/accelerate.git
#current version of Accelerate on GitHub breaks QLoRa
#Using standard pip instead
pip install -q -U accelerate
pip install -q -U datasets
Next, we can start writing the Python script.
Loading and Quantization of a GPT model
We need the following imports to load and quantize an LLM.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
For this demo, we will fine-tune the GPT NeoX model pre-trained by EleutherAI. This is a model with 20 billion parameters. Note: GPT NeoX has a permissive license (Apache 2.0) that allows commercial use.
We can get this model and the associated tokenizer from Hugging Face Hub:
model_name = "EleutherAI/gpt-neox-20b"
#Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
Then, we need to detail the configuration of the quantizer, as follows:
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
- load_in_4bit: The model will be loaded in the memory with 4-bit precision.
- bnb_4bit_use_double_quant: We will do the double quantization proposed by QLoRa.
- bnb_4bit_quant_type: This is the type of quantization. “nf4” stands for 4-bit NormalFloat.
- bnb_4bit_compute_dtype: While we load and store the model in 4-bit, we will partially dequantize it when needed and do all the computations with a 16-bit precision (bfloat16).
So now we can load the model in 4-bit:
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quant_config, device_map={"":0})
Then, we enable gradient checkpointing:
model.gradient_checkpointing_enable()
Preprocessing the GPT model for LoRa
This is where we use PEFT. We prepare the model for LoRa, adding trainable adapters for each layer.
from peft import prepare_model_for_kbit_training, LoraConfig, get_peft_model
model = prepare_model_for_kbit_training(model)
config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["query_key_value"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)
In LoraConfig, you can play with r, alpha, and dropout to obtain better results on your task. You can find more options and details in the PEFT repository.
With LoRa, we add only 8 million parameters. We will only train these parameters and freeze everything else. Fine-tuning should be fast.
Get your dataset ready
For this demo, I use the “english_quotes” dataset. This is a dataset made of famous quotes distributed under a CC BY 4.0 license.
from datasets import load_dataset
data = load_dataset("Abirate/english_quotes")
data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
Fine-tuning GPT-NeoX-20B with QLoRa
Finally, the fine-tuning with Hugging Face Transformers is very standard.
import transformers
tokenizer.pad_token = tokenizer.eos_token
trainer = transformers.Trainer(
model=model,
train_dataset=data["train"],
args=transformers.TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
warmup_steps=2,
max_steps=20,
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir="outputs",
optim="paged_adamw_8bit"
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
trainer.train()
Don’t forget optim=”paged_adamw_8bit”. It activates the paging for better memory management. Without it, we get out-of-memory errors.
Running this fine-tuning should only take 5 minutes on Google Colab.
The VRAM consumption should peak at 15 Gb.
And that’s it, we fine-tuned an LLM for free!
Does it work? Let’s try inference.
GPT Inference with QLoRa
The QLoRa model we fine-tuned can be directly used with the standard Hugging Face Transformers’ inference, as follows:
text = "Ask not what your country"
device = "cuda:0"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
You should get this quote as output:
Ask not what your country can do for you, ask what you can do for your country.”
– John F.
We got the expected quote. Not bad for 5 minutes of fine-tuning!
Conclusion
Large language models got bigger but, at the same time, we finally got the tools to do fine-tuning and inference on consumer hardware.
Thanks to LoRa, and now QLoRa, we can fine-tune models with billion parameters without relying on cloud computing and without a significant drop in performance according to the QLoRa paper.
If you have any problem running the code, please drop a comment, and I’ll try to help. You can also find more information about QLoRa implementation in the official GitHub repository.